完整版:
英文出处:。
由于本文是个长篇技术文章,涉及到很多算法和数据结构知识,你尽可以慢慢读。有些概念比较难懂,你可以跳过,不影响理解整体内容。
这篇文章大约分为3个部分:
- 底层和上层数据库组件概况
- 查询优化过程概况
- 事务和缓冲池管理概况
回到基础
很久很久以前(在一个遥远而又遥远的星系……),开发者必须确切地知道他们的代码需要多少次运算。他们把算法和数据结构牢记于心,因为他们的计算机运行缓慢,无法承受对CPU和内存的浪费。
在这一部分,我将提醒大家一些这类的概念,因为它们对理解数据库至关重要。我还会介绍数据库索引的概念。
O(1) vs O(n^2)
现今很多开发者不关心时间复杂度……他们是对的。
但是当你应对大量的数据(我说的可不只是成千上万哈)或者你要争取毫秒级操作,那么理解这个概念就很关键了。而且你猜怎么着,数据库要同时处理这两种情景!我不会占用你太长时间,只要你能明白这一点就够了。这个概念在下文会帮助我们理解什么是基于成本的优化。
概念
时间复杂度用来检验某个算法处理一定量的数据要花多长时间。为了描述这个复杂度,计算机科学家使用数学上的『』。这个表示法用一个函数来描述算法处理给定的数据需要多少次运算。
比如,当我说『这个算法是适用 O(某函数())』,我的意思是对于某些数据,这个算法需要 某函数(数据量) 次运算来完成。
重要的不是数据量,而是当数据量增加时运算如何增加。时间复杂度不会给出确切的运算次数,但是给出的是一种理念。

图中可以看到不同类型的复杂度的演变过程,我用了对数尺来建这个图。具体点儿说,数据量以很快的速度从1条增长到10亿条。我们可得到如下结论:
- 绿:O(1)或者叫常数阶复杂度,保持为常数(要不人家就不会叫常数阶复杂度了)。
- 红:O(log(n))对数阶复杂度,即使在十亿级数据量时也很低。
- 粉:最糟糕的复杂度是 O(n^2),平方阶复杂度,运算数快速膨胀。
- 黑和蓝:另外两种复杂度(的运算数也是)快速增长。
例子
数据量低时,O(1) 和 O(n^2)的区别可以忽略不计。比如,你有个算法要处理2000条元素。
- O(1) 算法会消耗 1 次运算
- O(log(n)) 算法会消耗 7 次运算
- O(n) 算法会消耗 2000 次运算
- O(n*log(n)) 算法会消耗 14,000 次运算
- O(n^2) 算法会消耗 4,000,000 次运算
O(1) 和 O(n^2) 的区别似乎很大(4百万),但你最多损失 2 毫秒,只是一眨眼的功夫。确实,当今处理器每秒可处理上亿次的运算。这就是为什么性能和优化在很多IT项目中不是问题。
我说过,面临海量数据的时候,了解这个概念依然很重要。如果这一次算法需要处理 1,000,000 条元素(这对数据库来说也不算大)。
- O(1) 算法会消耗 1 次运算
- O(log(n)) 算法会消耗 14 次运算
- O(n) 算法会消耗 1,000,000 次运算
- O(n*log(n)) 算法会消耗 14,000,000 次运算
- O(n^2) 算法会消耗 1,000,000,000,000 次运算
我没有具体算过,但我要说,用O(n^2) 算法的话你有时间喝杯咖啡(甚至再续一杯!)。如果在数据量后面加个0,那你就可以去睡大觉了。
继续深入
为了让你能明白
- 搜索一个好的哈希表会得到 O(1) 复杂度
- 搜索一个均衡的树会得到 O(log(n)) 复杂度
- 搜索一个阵列会得到 O(n) 复杂度
- 最好的排序算法具有 O(n*log(n)) 复杂度
- 糟糕的排序算法具有 O(n^2) 复杂度
注:在接下来的部分,我们将会研究这些算法和数据结构。
有多种类型的时间复杂度
- 一般情况场景
- 最佳情况场景
- 最差情况场景
时间复杂度经常处于最差情况场景。
这里我只探讨时间复杂度,但复杂度还包括:
- 算法的内存消耗
- 算法的磁盘 I/O 消耗
当然还有比 n^2 更糟糕的复杂度,比如:
- n^4:差劲!我将要提到的一些算法具备这种复杂度。
- 3^n:更差劲!本文中间部分研究的一些算法中有一个具备这种复杂度(而且在很多数据库中还真的使用了)。
- 阶乘 n:你永远得不到结果,即便在少量数据的情况下。
- n^n:如果你发展到这种复杂度了,那你应该问问自己IT是不是你的菜。
注:我并没有给出『大O表示法』的真正定义,只是利用这个概念。可以看看维基百科上的。
合并排序
当你要对一个集合排序时你怎么做?什么?调用 sort() 函数……好吧,算你对了……但是对于数据库,你需要理解这个 sort() 函数的工作原理。
优秀的排序算法有好几个,我侧重于最重要的一种:合并排序。你现在可能还不了解数据排序有什么用,但看完查询优化部分后你就会知道了。再者,合并排序有助于我们以后理解数据库常见的联接操作,即合并联接 。
合并
与很多有用的算法类似,合并排序基于这样一个技巧:将 2 个大小为 N/2 的已排序序列合并为一个 N 元素已排序序列仅需要 N 次操作。这个方法叫做合并。
我们用个简单的例子来看看这是什么意思:

通过此图你可以看到,在 2 个 4元素序列里你只需要迭代一次,就能构建最终的8元素已排序序列,因为两个4元素序列已经排好序了:
- 1) 在两个序列中,比较当前元素(当前=头一次出现的第一个)
- 2) 然后取出最小的元素放进8元素序列中
- 3) 找到(两个)序列的下一个元素,(比较后)取出最小的
- 重复1、2、3步骤,直到其中一个序列中的最后一个元素
- 然后取出另一个序列剩余的元素放入8元素序列中。
这个方法之所以有效,是因为两个4元素序列都已经排好序,你不需要再『回到』序列中查找比较。
【译者注:,其中一个动图(原图较长,我做了删减)清晰的演示了上述合并排序的过程,而原文的叙述似乎没有这么清晰,不动戳大。】

既然我们明白了这个技巧,下面就是我的合并排序伪代码。
| 1 2 3 4 5 6 7 8 9 10 11 12 13 | array mergeSort(array a) if(length(a)==1) return a[0]; end if //recursive calls [left_array right_array] := split_into_2_equally_sized_arrays(a); array new_left_array := mergeSort(left_array); array new_right_array := mergeSort(right_array); //merging the 2 small ordered arrays into a big one array result := merge(new_left_array,new_right_array); return result; |
合并排序是把问题拆分为小问题,通过解决小问题来解决最初的问题(注:这种算法叫分治法,即『分而治之、各个击破』)。如果你不懂,不用担心,我第一次接触时也不懂。如果能帮助你理解的话,我认为这个算法是个两步算法:
- 拆分阶段,将序列分为更小的序列
- 排序阶段,把小的序列合在一起(使用合并算法)来构成更大的序列
拆分阶段

在拆分阶段过程中,使用3个步骤将序列分为一元序列。步骤数量的值是 log(N) (因为 N=8, log(N)=3)。【译者注:底数为2,下文有说明】
我怎么知道这个的?
我是天才!一句话:数学。道理是每一步都把原序列的长度除以2,步骤数就是你能把原序列长度除以2的次数。这正好是对数的定义(在底数为2时)。
排序阶段

在排序阶段,你从一元序列开始。在每一个步骤中,你应用多次合并操作,成本一共是 N=8 次运算。
- 第一步,4 次合并,每次成本是 2 次运算。
- 第二步,2 次合并,每次成本是 4 次运算。
- 第三步,1 次合并,成本是 8 次运算。
因为有 log(N) 个步骤,整体成本是 N*log(N) 次运算。
【译者注:这个完整的动图演示了拆分和排序的全过程,不动戳大。】

合并排序的强大之处
为什么这个算法如此强大?
因为:
- 你可以更改算法,以便于节省内存空间,方法是不创建新的序列而是直接修改输入序列。
注:这种算法叫『原地算法』()
- 你可以更改算法,以便于同时使用磁盘空间和少量内存而避免巨量磁盘 I/O。方法是只向内存中加载当前处理的部分。在仅仅100MB的内存缓冲区内排序一个几个GB的表时,这是个很重要的技巧。
注:这种算法叫『外部排序』()。
- 你可以更改算法,以便于在 多处理器/多线程/多服务器 上运行。
比如,分布式合并排序是(那个著名的大数据框架)的关键组件之一。
- 这个算法可以点石成金(事实如此!)
这个排序算法在大多数(如果不是全部的话)数据库中使用,但是它并不是唯一算法。如果你想多了解一些,你可以看看 ,探讨的是数据库中常用排序算法的优势和劣势。
阵列,树和哈希表
既然我们已经了解了时间复杂度和排序背后的理念,我必须要向你介绍3种数据结构了。这个很重要,因为它们是现代数据库的支柱。我还会介绍数据库索引的概念。
阵列
二维阵列是最简单的数据结构。一个表可以看作是个阵列,比如:
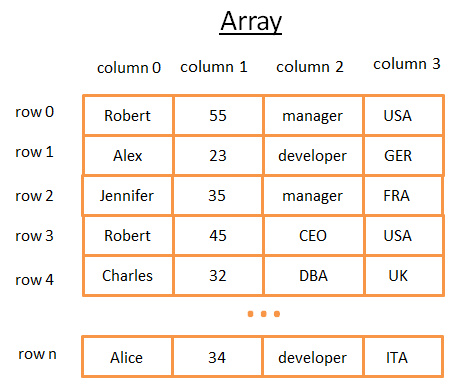
这个二维阵列是带有行与列的表:
- 每个行代表一个主体
- 列用来描述主体的特征
- 每个列保存某一种类型对数据(整数、字符串、日期……)
虽然用这个方法保存和视觉化数据很棒,但是当你要查找特定的值它就很糟糕了。 举个例子,如果你要找到所有在 UK 工作的人,你必须查看每一行以判断该行是否属于 UK 。这会造成 N 次运算的成本(N 等于行数),还不赖嘛,但是有没有更快的方法呢?这时候树就可以登场了(或开始起作用了)。
树和数据库索引
二叉查找树是带有特殊属性的二叉树,每个节点的关键字必须:
- 比保存在左子树的任何键值都要大
- 比保存在右子树的任何键值都要小
【译者注:binary search tree,二叉查找树/二叉搜索树,或称 Binary Sort Tree 二叉排序树。见 】
概念
这个树有 N=15 个元素。比方说我要找208:
- 我从键值为 136 的根开始,因为 136<208,我去找节点136的右子树。
- 398>208,所以我去找节点398的左子树
- 250>208,所以我去找节点250的左子树
- 200<208,所以我去找节点200的右子树。但是 200 没有右子树,值不存在(因为如果存在,它会在 200 的右子树)
现在比方说我要找40
- 我从键值为136的根开始,因为 136>40,所以我去找节点136的左子树。
- 80>40,所以我去找节点 80 的左子树
- 40=40,节点存在。我抽取出节点内部行的ID(图中没有画)再去表中查找对应的 ROW ID。
- 知道 ROW ID我就知道了数据在表中对精确位置,就可以立即获取数据。
最后,两次查询的成本就是树内部的层数。如果你仔细阅读了合并排序的部分,你就应该明白一共有 log(N)层。所以这个查询的成本是 log(N),不错啊!
回到我们的问题
上文说的很抽象,我们回来看看我们的问题。这次不用傻傻的数字了,想象一下前表中代表某人的国家的字符串。假设你有个树包含表中的列『country』:
- 如果你想知道谁在 UK 工作
- 你在树中查找代表 UK 的节点
- 在『UK 节点』你会找到 UK 员工那些行的位置
这次搜索只需 log(N) 次运算,而如果你直接使用阵列则需要 N 次运算。你刚刚想象的就是一个数据库索引。
B+树索引
查找一个特定值这个树挺好用,但是当你需要查找两个值之间的多个元素时,就会有大麻烦了。你的成本将是 O(N),因为你必须查找树的每一个节点,以判断它是否处于那 2 个值之间(例如,对树使用中序遍历)。而且这个操作不是磁盘I/O有利的,因为你必须读取整个树。我们需要找到高效的范围查询方法。为了解决这个问题,现代数据库使用了一种修订版的树,叫做B+树。在一个B+树里:
- 只有最底层的节点(叶子节点)才保存信息(相关表的行位置)
- 其它节点只是在搜索中用来指引到正确节点的。
【译者注:参考 , 】
你可以看到,节点更多了(多了两倍)。确实,你有了额外的节点,它们就是帮助你找到正确节点的『决策节点』(正确节点保存着相关表中行的位置)。但是搜索复杂度还是在 O(log(N))(只多了一层)。一个重要的不同点是,最底层的节点是跟后续节点相连接的。
用这个 B+树,假设你要找40到100间的值:
- 你只需要找 40(若40不存在则找40之后最贴近的值),就像你在上一个树中所做的那样。
- 然后用那些连接来收集40的后续节点,直到找到100。
比方说你找到了 M 个后续节点,树总共有 N 个节点。对指定节点的搜索成本是 log(N),跟上一个树相同。但是当你找到这个节点,你得通过后续节点的连接得到 M 个后续节点,这需要 M 次运算。那么这次搜索只消耗了 M+log(N) 次运算,区别于上一个树所用的 N 次运算。此外,你不需要读取整个树(仅需要读 M+log(N) 个节点),这意味着更少的磁盘访问。如果 M 很小(比如 200 行)并且 N 很大(1,000,000),那结果就是天壤之别了。
然而还有新的问题(又来了!)。如果你在数据库中增加或删除一行(从而在相关的 B+树索引里):
- 你必须在B+树中的节点之间保持顺序,否则节点会变得一团糟,你无法从中找到想要的节点。
- 你必须尽可能降低B+树的层数,否则 O(log(N)) 复杂度会变成 O(N)。
换句话说,B+树需要自我整理和自我平衡。谢天谢地,我们有智能删除和插入。但是这样也带来了成本:在B+树中,插入和删除操作是 O(log(N)) 复杂度。所以有些人听到过使用太多索引不是个好主意这类说法。没错,你减慢了快速插入/更新/删除表中的一个行的操作,因为数据库需要以代价高昂的每索引 O(log(N)) 运算来更新表的索引。再者,增加索引意味着给事务管理器带来更多的工作负荷(在本文结尾我们会探讨这个管理器)。
想了解更多细节,你可以看看 Wikipedia 上这篇。如果你想要数据库中实现B+树的例子,看看MySQL核心开发人员写的 和 。两篇文章都致力于探讨 innoDB(MySQL引擎)如何处理索引。
哈希表
我们最后一个重要的数据结构是哈希表。当你想快速查找值时,哈希表是非常有用的。而且,理解哈希表会帮助我们接下来理解一个数据库常见的联接操作,叫做『哈希联接』。这个数据结构也被数据库用来保存一些内部的东西(比如锁表或者缓冲池,我们在下文会研究这两个概念)。
哈希表这种数据结构可以用关键字来快速找到一个元素。为了构建一个哈希表,你需要定义:
- 元素的关键字
- 关键字的哈希函数。关键字计算出来的哈希值给出了元素的位置(叫做哈希桶)。
- 关键字比较函数。一旦你找到正确的哈希桶,你必须用比较函数在桶内找到你要的元素。
一个简单的例子
我们来看一个形象化的例子:

这个哈希表有10个哈希桶。因为我懒,我只给出5个桶,但是我知道你很聪明,所以我让你想象其它的5个桶。我用的哈希函数是关键字对10取模,也就是我只保留元素关键字的最后一位,用来查找它的哈希桶:
- 如果元素最后一位是 0,则进入哈希桶0,
- 如果元素最后一位是 1,则进入哈希桶1,
- 如果元素最后一位是 2,则进入哈希桶2,
- …我用的比较函数只是判断两个整数是否相等。
【译者注:】
比方说你要找元素 78:
- 哈希表计算 78 的哈希码,等于 8。
- 查找哈希桶 8,找到的第一个元素是 78。
- 返回元素 78。
- 查询仅耗费了 2 次运算(1次计算哈希值,另一次在哈希桶中查找元素)。
现在,比方说你要找元素 59:
- 哈希表计算 59 的哈希码,等于9。
- 查找哈希桶 9,第一个找到的元素是 99。因为 99 不等于 59, 那么 99 不是正确的元素。
- 用同样的逻辑,查找第二个元素(9),第三个(79),……,最后一个(29)。
- 元素不存在。
- 搜索耗费了 7 次运算。
一个好的哈希函数
你可以看到,根据你查找的值,成本并不相同。
如果我把哈希函数改为关键字对 1,000,000 取模(就是说取后6位数字),第二次搜索只消耗一次运算,因为哈希桶 00059 里面没有元素。真正的挑战是找到好的哈希函数,让哈希桶里包含非常少的元素。
在我的例子里,找到一个好的哈希函数很容易,但这是个简单的例子。当关键字是下列形式时,好的哈希函数就更难找了:
- 1 个字符串(比如一个人的姓)
- 2 个字符串(比如一个人的姓和名)
- 2 个字符串和一个日期(比如一个人的姓、名和出生年月日)
- …
如果有了好的哈希函数,在哈希表里搜索的时间复杂度是 O(1)。
阵列 vs 哈希表
为什么不用阵列呢?
嗯,你问得好。
- 一个哈希表可以只装载一半到内存,剩下的哈希桶可以留在硬盘上。
- 用阵列的话,你需要一个连续内存空间。如果你加载一个大表,很难分配足够的连续内存空间。
- 用哈希表的话,你可以选择你要的关键字(比如,一个人的国家和姓氏)。
想要更详细的信息,你可以阅读我在 上的文章,是关于高效哈希表实现的。你不需要了解Java就能理解文章里的概念。
全局概览
我们已经了解了数据库内部的基本组件,现在我们需要回来看看数据库的全貌了。
数据库是一个易于访问和修改的信息集合。不过简单的一堆文件也能达到这个效果。事实上,像SQLite这样最简单的数据库也只是一堆文件而已,但SQLite是精心设计的一堆文件,因为它允许你:
- 使用事务来确保数据的安全和一致性
- 快速处理百万条以上的数据
数据库一般可以用如下图形来理解:

撰写这部分之前,我读过很多书/论文,它们都以自己的方式描述数据库。所以,我不会特别关注如何组织数据库或者如何命名各种进程,因为我选择了自己的方式来描述这些概念以适应本文。区别就是不同的组件,总体思路为:数据库是由多种互相交互的组件构成的。
核心组件:
- 进程管理器(process manager):很多数据库具备一个需要妥善管理的进程/线程池。再者,为了实现纳秒级操作,一些现代数据库使用自己的线程而不是操作系统线程。
- 网络管理器(network manager):网路I/O是个大问题,尤其是对于分布式数据库。所以一些数据库具备自己的网络管理器。
- 文件系统管理器(File system manager):磁盘I/O是数据库的首要瓶颈。具备一个文件系统管理器来完美地处理OS文件系统甚至取代OS文件系统,是非常重要的。
- 内存管理器(memory manager):为了避免磁盘I/O带来的性能损失,需要大量的内存。但是如果你要处理大容量内存你需要高效的内存管理器,尤其是你有很多查询同时使用内存的时候。
- 安全管理器(Security Manager):用于对用户的验证和授权。
- 客户端管理器(Client manager):用于管理客户端连接。
- ……
工具:
- 备份管理器(Backup manager):用于保存和恢复数据。
- 复原管理器(Recovery manager):用于崩溃后重启数据库到一个一致状态。
- 监控管理器(Monitor manager):用于记录数据库活动信息和提供监控数据库的工具。
- Administration管理器(Administration manager):用于保存元数据(比如表的名称和结构),提供管理数据库、模式、表空间的工具。【译者注:好吧,我真的不知道Administration manager该翻译成什么,有知道的麻烦告知,不胜感激……】
- ……
查询管理器:
- 查询解析器(Query parser):用于检查查询是否合法
- 查询重写器(Query rewriter):用于预优化查询
- 查询优化器(Query optimizer):用于优化查询
- 查询执行器(Query executor):用于编译和执行查询
数据管理器:
- 事务管理器(Transaction manager):用于处理事务
- 缓存管理器(Cache manager):数据被使用之前置于内存,或者数据写入磁盘之前置于内存
- 数据访问管理器(Data access manager):访问磁盘中的数据
在本文剩余部分,我会集中探讨数据库如何通过如下进程管理SQL查询的:
-
- 客户端管理器
- 查询管理器
- 数据管理器(含复原管理器)